
Analyzing Sentiment in Caltrain Tweets
As a first step to using Twitter activity as one of the data sources for train prediction, we start with a simple question: How do Twitter users currently feel about Caltrain?
Ben has a background in computational biophysics, where he leveraged complex bioinformatic data to build functional proteins from scratch. He is excited about applying advanced mathematical modeling and machine learning techniques to test hypotheses and deliver elegant solutions to the most difficult problems.
As a first step to using Twitter activity as one of the data sources for train prediction, we start with a simple question: How do Twitter users currently feel about Caltrain?

In this post, we’ll start to develop an intuition for how to approach the remaining useful life (RUL) estimation problem and take the first steps in modeling RUL.

In this post, we’ll cut through some of the ambiguity around IoT applications, and introduce an example data science problem relevant to the IoT world.

In this post, we will look at driving product engagement with behavioral data, as well as building an integrated analytical environment.

The promise of data and analytics for product companies is that they can help you understand usage, and improve your ability to build, deploy, and service products to customers much more accurately and efficiently. In this post, we look at understanding the customer life cycle.
An expert in quantitative modeling, Jeffrey brings over 17 years of experience applying econometric, statistic, and mathematical modeling techniques to real-world challenges. He brings a strong background in finance as well as a passion for leading data science teams in finding innovative solutions to challenging business problems.
Many of us will be at Strata in San Jose, and we’d love to see you there! Come learn more about data platforms, data strategy, business tools, and more.
CTO John Akred, VP of Data Science Jeffrey Yau, and Senior Data Scientist Cindi Thompson will teach a three-hour tutorial in which they will share our methods and observations from three years of effectively deploying data science in enterprise organizations. Attendees will learn how to be an effective member or manager of a data science team.
Several of us will be in Chicago this year, presenting tutorials on data strategy, data platforms, and how to manage data science in the enterprise. CTO John Akred will also be taking part in a panel about how to strengthen your data strategy skills.
We’ll be at PyData, looking to learn more about how data scientists are using Python. Have a cool story, or questions of your own? Be sure to come find us.
VP of Data Science Jeffrey Yau, along with Data Scientists Chloe Mawer and Daniel Margala, will be presenting on predicting train delays. See more about our train work here.
Come hear from practitioners and scholars who are designing new data science tools and applications and using data in meaningful and beneficial ways, including CTO John Akred and VP of Data Science Jeffrey Yau.
Join us for a demo and talk on our Caltrain Rider app, which presents an intuitive view of the Caltrain systems using data from our own sensors (video, audio) combined with publicly available data from Twitter and the Caltrain API.
A leading expert on big data architecture, infrastructure, and technical operations, Stephen brings over 20 years of experience creating scalable, high-availability, data and applications solutions. He has deep experience in Hadoop usage and architecture and other cutting-edge open source solutions.
Prior to SVDS, Stephen created and led the next-generation data platform team at Walmart Labs as a Senior Director. He and his team architected and designed the data platform used by all of Walmart’s e-commerce business units. Stephen evaluated, made recommendations and built solutions to address Walmart’s needs in security, high availability, scalability and performance. Prior to Walmart Labs, his tenure covers over three years as Director of System Engineering at LiveOps, running data, reporting, and API teams; three years in data management at Yahoo’s search group; and eleven years as a Senior Engineer at Sun Microsystems.
Stephen is a patent-holder and a sought-after presenter at major industry conferences.

Building or rebuilding a data platform can be a daunting task, as most questions that need to be asked have open-ended answers. But that doesn’t mean you have to guess and use your gut.

Several of our presenters were interviewed at Strata San Jose. If you missed the conference, check out these interviews below to catch up on some of the topics that were on our minds.

Building or rebuilding a data platform can be a daunting task, as most questions that need to be asked have open-ended answers. This post aims to help.

Check out the slides from our recent presentations at Data Day TX and Graph Day.

Graphite is a tool that does two things rather well: storing numeric time-series data (metric, value, epoch timestamp), and rendering graphs of this data on demand.
The Data Architecture Summit provides in-depth education from leading experts specializing in data architecture. We will be there discussing data platform and data governance. Let us know if you you’ll be attending and would like to chat.
The Strata Data Conference is where cutting-edge science and new business fundamentals intersect—and merge. Several of us will be there in September, discussing platforms, strategy, and tools. Let us know if you’ll be attending and would like to chat.
Stephen O’Sullivan, VP of Data Engineering at SVDS, is the featured guest speaker at this event hosted by The Data Lab at the Balmoral Hotel.
Join us at our Spark Summit sessions in San Francisco, where we’ll be giving a tutorial on data platforms, as well as sessions on PySpark and Graph Algorithms. Find CTO John Akred, VP of Engineering Stephen O’Sullivan, or Principal Data Engineer and Spark Contributor Andrew Ray to talk more.
Strata + Hadoop World London focuses on how to make data-driven decisions across industries. Several of us will be there in May, discussing platforms, strategy, and tools. Let us know if you’ll be attending and would like to chat.
This year we’re teaming up with Red Hat to discuss analytics frameworks, and how you can get the most out of your data.
DataEngConf features talks and workshops aimed at bridging the gap between data scientists, data engineers, and data analysts. We’ll be there, giving tips on choosing the right format for your data.
Enterprise Data World focuses on data-driven business. Several of us will be there this year, talking about data platforms and enterprise data science. Let us know if you’ll be there, or you can sign up to receive our slides.
Many of us will be at Strata in San Jose, and we’d love to see you there! Come learn more about data platforms, data strategy, business tools, and more.
We’re heading to Texas in January to talk about data pipelines with Kafka and Spark.
The SVDS crew will be in New York this year, talking about data platforms, data strategy, and making the business case for Spark. Come by our talks, or catch us in the hallway track.
Several of us will be in Chicago this year, presenting tutorials on data strategy, data platforms, and how to manage data science in the enterprise. CTO John Akred will also be taking part in a panel about how to strengthen your data strategy skills.
Join us as CTO John Akred gives a talk on alternative approaches to valuing data within an organization, and Data Scientist Chloe Mawer demonstrates the power of Jupyter notebooks using a real-world train-detection problem. We’ll also present a tutorial on building data pipelines with Kafka and Spark.
Several of us will be presenting, talking about platforms, strategies, and tools. We’ve love to see you there! Join us for our tutorials and sessions, or come ask questions during our Office Hour.
Several of us will be at Enterprise Data World 2016 in San Diego. We’d love to say hi, and hear your thoughts.
Many of us will be at the Strata Conference + Hadoop World 2016 in San Jose, and we’d love to see you there!
Join CTO John Akred for a talk on Running Agile Data Science Teams, and VP of Engineering Stephen O’Sullivan for a talk on Choosing an HDFS data storage format (Avro vs. Parquet). Principal Engineer Mark Mims will hold Office Hours.
Join us for a demo and talk on our Caltrain Rider app, which presents an intuitive view of the Caltrain systems using data from our own sensors (video, audio) combined with publicly available data from Twitter and the Caltrain API.
SVDS presents two tutorials: one on Data Strategy and one on building a Data Platform. In addition, Edd Dumbill participates in a panel, “The Data-Driven Organization – New Roles and Relationships.”
Several of us will be at the Strata + Hadoop World 2015 Conference in New York in September and we’d love to see you there. Join us for our tutorials and sessions, or come visit us at our booth in the Expo Hall.
What are the essential components of a data platform? SVDS presents a tutorial that will explain how the various parts of the Hadoop and big data ecosystem fit together in production to create a data platform supporting batch, interactive and real-time analytical workloads.
SVDS presents two sessions at StampedeCon: one that examines the benefits of using multiple persistence strategies to build an end-to-end predictive engine; and a look at how to choose an HDFS data storage format: Avro vs. Parquet and more.
SVDS presents two sessions at Hadoop Summit: one that maps the central concepts in Spark to those in the SAS language, including datasets, queries, and machine learning; and a look at how to choose an HDFS data storage format: Avro vs. Parquet and more.
Several of us will be presenting and we’d love to see you there. Join us for our tutorials and sessions, or come visit us at our booth in the Expo Hall.
Responsible for architecting solutions and driving them through to completion, Serena draws from over a decade of experience in engineering and architecture work, focusing particularly on complex, high-volume, low-latency, enterprise-wide systems. Her previous work spans a variety of industries including financial services, retail, telecommunications, transportation, and gaming.
At SVDS, she has led architecture advisory, agile data science, and agile data engineering projects. Most recently, she has led an effort that built an enterprise-wide distributed data platform for a large retailer that enables use cases across the business, from customer recommendations for loyalty, to meeting regulatory requirements for the bank division. For another global client, she led multiple data science teams driving insights on how products, trends, labels, seasons, release cycles, and other features affect the behavior of customers both online and in stores.
Prior to joining SVDS, Serena was a Senior Manager at Accenture, managing large technical projects with on- and off-shore teams against tight timelines.
Rick has extensive experience with a wide variety of technical and execution architectures, including big data platforms, data services and SOA, virtualization, infrastructure, security, integration, distributed computing, and data transformation. He has led pioneering client delivery engagements including the delivery of NetApp’s Next Generation Phone Home data platform utilizing Hadoop, HBase, and Cassandra. He also led the delivery of a multi-tenant, hybrid use case big data platform for a large datacenter co-location provider. That platform was built using Cassandra and Storm to facilitate multiple different use cases in a centralized manner.
Rick has deep experience in the creation of vertical solutions that include everything from cloud-based infrastructure and big data storage techniques to predictive analytics and custom visualization solutions. He has built solutions utilizing tools such as Cassandra, Hadoop, HBase, Hive, Pig, Storm, Solr, Flume, Pentaho, and custom Java development.

In this post, we will discuss how dealing with small files is different if you are using MapR-FS rather than the traditional HDFS installation.
An Apache Cassandra committer and PMC member, Gary specializes in building distributed systems. Recent experience includes creating an open source high-volume metrics processing pipeline and building out several geographically distributed API services in the cloud.

In this tutorial, we will walk you through some of the basics of using Kafka and Spark to ingest data.
Building or rebuilding a data platform can be a daunting task, as most questions that need to be asked have open-ended answers. But that doesn’t mean you have to guess and use your gut.
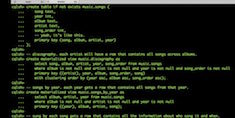
In this screencast, Principal Engineer and Cassandra committer Gary Dusbabek provides an overview of Materialized Views.
Building or rebuilding a data platform can be a daunting task, as most questions that need to be asked have open-ended answers. This post aims to help.

Microservices are a popular topic in developer circles, because they are a means of solving problems that have plagued monolithic software projects for decades. Namely, tardiness and bugs, both caused by complexity.
OSCON is a long-running conference focused on open source technology and communities. We’ll be there talking about our “push button” infrastructure tool.
Several of us will be at Enterprise Data World 2016 in San Diego. We’d love to say hi, and hear your thoughts.
Many of us will be at the Strata Conference + Hadoop World 2016 in San Jose, and we’d love to see you there!
SVDS presents two tutorials: one on Data Strategy and one on building a Data Platform. In addition, Edd Dumbill participates in a panel, “The Data-Driven Organization – New Roles and Relationships.”
Several of us will be at the Strata + Hadoop World 2015 Conference in New York in September and we’d love to see you there. Join us for our tutorials and sessions, or come visit us at our booth in the Expo Hall.
SVDS presents two sessions at the Cassandra Summit: a look at the migration of our client Allant’s CDI-keying engine from Oracle to Cassandra; and a how-to on using Cassandra as a platform for building a custom distributed system.
What are the essential components of a data platform? SVDS presents a tutorial that will explain how the various parts of the Hadoop and big data ecosystem fit together in production to create a data platform supporting batch, interactive and real-time analytical workloads.
Tom has over 20 years experience applying machine learning and data science across five different companies. He is co-author of the highly regarded and top-selling book Data Science for Business (O’Reilly, 2013), which is now used in over 140 universities around the world.
Prior to joining SVDS, as a senior architect at Proofpoint, Tom applied machine learning techniques, including social network analysis and probabilistic inference, to email analysis and filtering. While at Stanford’s Center for the Study of Language and Information, he led a DARPA-sponsored project on Transfer Learning. He has also held senior research scientist positions at HP Labs, NYNEX, and GTE Labs.
Tom holds a Ph.D. in Computer Science (Machine Learning) from the University of Massachusetts, Amherst. He is an action editor of Machine Learning Journal; he also serves on the editorial boards of the journals Data Mining and Knowledge Discovery and Big Data, as well as on the advisory board of the Berkeley Extension Data Science Program.
For this month’s Throwback Thursday, a post that provides insight and concrete advice on how to tackle imbalanced data.

Business leaders cannot afford to ignore their organization’s data—rather, that data should be used to make informed decisions. In this post, Principal Data Scientist Tom Fawcett and Professor of Data […]

You should understand whether the right things have been measured and whether the results are suitable for the business problem.

We (Tom, a Machine Learning practitioner, and Drew, a professional Statistician) have worked together for several years. We believe we have an understanding of the role of each field within data science, which we attempt to articulate here.
In this post, we will look at driving product engagement with behavioral data, as well as building an integrated analytical environment.
The promise of data and analytics for product companies is that they can help you understand usage, and improve your ability to build, deploy, and service products to customers much more accurately and efficiently. In this post, we look at understanding the customer life cycle.
In this post, we will explore some aspects of the train delay data we’ve been collecting from the Caltrain API.
A basic mantra in statistics and data science is correlation is not causation, meaning that just because two things appear to be related to each other doesn’t mean that one causes the other. This is a lesson worth learning.

Here we share some further thoughts on imbalanced classes, and offer more resources.

This post gives insight and concrete advice on how to tackle imbalanced data.

In this post, we will explore some aspects of the train delay data we’ve been collecting from the Caltrain API over the past few months. The goal is to get our heads into the data before setting off on building a prediction model.

A previous blog post made the point that classifiers shouldn’t use classification accuracy as a performance metric. The next part in this series was going to discuss other evaluation techniques such as ROC curves, profit curves, and lift curves. However, there are several important points to be made first. Here I present a sequence that shows the progression and inter-relation of the issues.

If it’s easy, it’s probably wrong.

A basic mantra in statistics and data science is correlation is not causation. This is a lesson worth learning.

As an R&D project, we have been playing with data science techniques to understand and predict delays in the Caltrain system.
With an extensive background in both computer science and statistics, Drew enjoys exploring data and finding insights. He is equally interested in the engineering required to build working, maintainable software solutions.
We (Tom, a Machine Learning practitioner, and Drew, a professional Statistician) have worked together for several years. We believe we have an understanding of the role of each field within data science, which we attempt to articulate here.
Paul is an experienced engineering leader, with a strong history in Silicon Valley. Bringing a background in extremely large big data clusters, he blends scale and operations with the know-how to deliver business-driven analytics and applications.
Paul is an experienced engineering leader, with a demonstrated track record at many of Silicon Valley’s leading engineering firms. He has extensive experience building end-to-end data platforms for numerous Fortune 100 companies. Prior to joining SVDS, Paul built, stood-up, and supported one of the two Hadoop clusters at Walmart.com and Walmart Labs, with nodes of up to 1500 machines. He architected a complete Hadoop ecosystem including Hue, HDFS, MapReduce, Hive, Hbase, Pig, and Oozie components. He implemented best practices for cluster administration including MapReduce jobs for fraud detection, investigation of site problems through server logs, analysis of DOS attack sources. He also built the first recommendation engine for Walmart.com. Prior to Walmart, Paul held engineer positions at Sun Microsystems and Silicon Graphics.
Paul holds a Bachelor of Science in Electrical Engineering and Computer Science from the Illinois Institute of Technology.