
Analyzing Sentiment in Caltrain Tweets
November 21st, 2017
Many of us here at SVDS rely on Caltrain, Silicon Valley’s commuter rail line, to commute to and from the office every day. As part of an ongoing R&D effort, we have been collecting and analyzing various sources of Caltrain-related data with the goal of determining where each train is, and how far behind schedule it’s currently running. In addition to video cameras and microphones, we use social networking platforms as sources of signal to detect service disruptions or delays as they’re reported on by the affected passengers.
Twitter is a popular place for people to vent their frustrations or update their fellow passengers on the current state of public transportation, and as such it’s a potentially valuable source of real-time data on Caltrain service. As a first step to using Twitter activity as one of the data sources for train prediction, we start with a simple question: How do Twitter users currently feel about Caltrain?
This type of problem is well-studied in natural language processing (NLP) and machine learning, and can be cast as a classification task: given the content of a document (e.g., a tweet), classify its overall sentiment as either positive or negative (aka polarity classification); we give a few examples of this at the end of the post.
The applications of sentiment analysis range from monitoring customer reactions to products and services, to providing a signal to predict future purchase behavior. In this post, we outline the different types of sentiment analysis, explore typical approaches, and walk you through an introductory example of training and evaluating a classifier using Python’s scikit-learn.
Introduction to Sentiment Analysis
The earliest sentiment analysis research dates to 2003 (Nasukawa and Yi), but has its roots in academic research in analysis of subjectivity as early as the 1990s. Its growth in more recent years parallels the growth of social media and other forms of user generated content. Sentiment analysis uses computational techniques to study people’s opinions, emotions, and attitudes as expressed by their language including emojis and emoticons.
Like the broader field of natural language processing (NLP), sentiment analysis is challenging due to many factors such as the ambiguity of language and the need for world knowledge in order to understand the context of many statements. Sentiment analysis includes the additional challenge that two people can read the same text and differ in their interpretation of its sentiment. In this post, we add another challenge, which is the short snippets of text, as well as slang, hashtags, and emoticons, which characterize tweets.
We focus here on polarity classification at the tweet level, but note that there are other levels of granularity that could be studied:
- At the least granular, document-level sentiment classification evaluates the polarity of entire documents such as a product review or news article.
- The next level is to decide whether a given sentence within a document is positive, negative, or neutral. In addition to polarity classification, other types of classification include assigning the number of “stars” to the text and assigning emotions such as fear or anger.
- Finally, aspect-based sentiment analysis (also called targeted or granular sentiment analysis) reveals deeper information about the content of the likes or dislikes expressed in text. For example, “The pizza was delicious but the service was shoddy” includes positive sentiment about pizza but negative sentiment about the service.
Approaches to sentiment analysis include those from NLP, statistics, and machine learning (ML). We focus here on a mix of NLP and ML approaches. There are two main aspects to this: feature engineering and model creation. We discuss the latter further below. Feature engineering in NLP is always tricky, and this is the case with social media-based sentiment analysis as well. Our example will skim the surface with bag-of-words (BOW), but other possibilities include TF-IDF, negation handling, n-grams, part-of-speech tagging, and the use of sentiment lexicons. More recently, there has been an explosion of approaches using deep learning and related techniques such as word2vec and doc2vec.
Finally, though we don’t touch on neural network techniques such as word2vec in this post, we note that they have made an impact in sentiment analysis as with other parts of NLP.
Gathering the Training Data
In order to train a classification model, we first need a large set of tweets that have been pre-labeled with their sentiment. Although it’s possible to generate such a dataset manually, we’ll save time and effort by using the Twitter US Airline Sentiment dataset, which consists of around 15,000 tweets about six major US airlines, hand-labeled as expressing either positive, negative, or neutral sentiment. Even though this dataset is about air travel, its tweets often express ideas relevant to Caltrain—complaints about delays, status updates, and (sometimes) expressions of gratitude for a smooth trip.
Once we’ve downloaded, reading in and checking out the data is straightforward:
# read the data
tweets = pd.read_csv('../data/Tweets.csv.zip')
# show the first few rows
tweets[['tweet_id','airline_sentiment','text']].head()
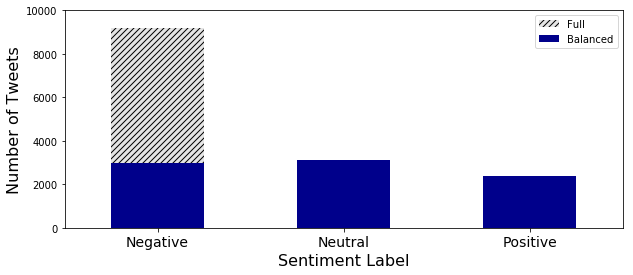
Before training a classifier in any domain, it’s important to understand the distribution of classes present in the training data. The total height of each bar in the figure below represents the count of tweets in each class. Unsurprisingly for this domain, most of the tweets are negative. Because we want to keep this introductory post simple, we will balance the classes. To read more about considerations for imbalanced data, check out this post. To address the class imbalance, we randomly sample 3,000 tweets from the “negative” class, and use this balanced set in the subsequent analysis. The blue region in the figure represents the distribution of classes after sampling.
Generating Feature Representations
Classification algorithms generally require their input to be in the form of a fixed-length feature vector. Thus, our first task is to ‘vectorize’ each tweet in a way that preserves as much of the meaning of the text as possible. As mentioned in the introduction, there are a number of ways of generating such feature vectors, and we will keep things simple for this introductory post.
For our purposes, we’ll start with a simple yet effective bag-of-words approach: represent each tweet as an N-dimensional vector, where N is number of unique words in our vocabulary. In the simplest version of this scheme, this vector is binary—each component is 1 if that specific word is present in the tweet, or 0 otherwise; as discussed in Chapter 6 of Jurafsky and Martin, 17, binary vectors typically outperform counts for sentiment analysis. Scikit-learn’s CountVectorizer is a handy tool generating this representation from an input set of strings:
# extract the training data, and sentiment labels txt_train, sentiment = tweets_balanced['text'], tweets_balanced['airline_sentiment']) # instantiate the count vectorizer cv = CountVectorizer(binary=True) # transform text txt_train_bow = cv.fit_transform(txt_train)
Training a Classifier
With our feature vectors in hand, we now have everything we need to train a classifier. But which one? The Naive Bayes classifier is a good starting point: not only is it conceptually simple and quick to train on a large data set, but it has also been shown to perform particularly well on text classification tasks like these.1 This model assumes that each word in a tweet independently contributes to the probability that the tweet belongs to a particular class c (i.e. ‘negative’, ‘neutral’, or ‘positive’). In particular, the conditional probability of a tweet d belonging to class c is modeled as:
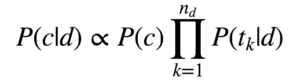
Where P(c) is the overall prior probability of the class, t_k is the kth word in the tweet, and n_d is the number of words in the tweet. To train the model, probabilities are computed by simply counting the relative frequencies of words or tweets in the training set, which is fast even on large training sets. Below, we instantiate scikit-learn’s out-of-the-box implementation of this model:
# our naive bayes model nb_sent_multi = MultinomialNB()
Evaluation
In order to evaluate the performance of this model on new tweets, we’ll look at two diagnostics, both computed using a five-fold cross validation procedure. It’s beyond the scope of this post to discuss cross validation; if you’re interested, the scikit-learn site has a basic overview. The first is a confusion matrix, shown below. The columns in the matrix represent the true classes, the rows represent the classes predicted by the model, and each entry is the number of tweets in the test set(s) that correspond to those class assignments.
# Run confusion matrix on transformed text and cross-validation predictions from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix sentiment_predict = cross_val_predict(nb_sent_multi, txt_train_bow, sentiment, cv=5) confusion_mat = confusion_matrix(sentiment, sentiment_predict)
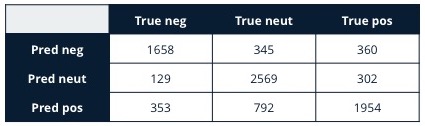
The first thing to notice from the confusion matrix is that the counts are mostly concentrated along the diagonal, indicating that the model is doing a reasonable job of assigning the true sentiment to tweets. Nevertheless, a sizeable portion are incorrectly classified in one way or another. In particular, the model falsely classifies a large portion of neutral tweets as positive (bottom row, middle column).
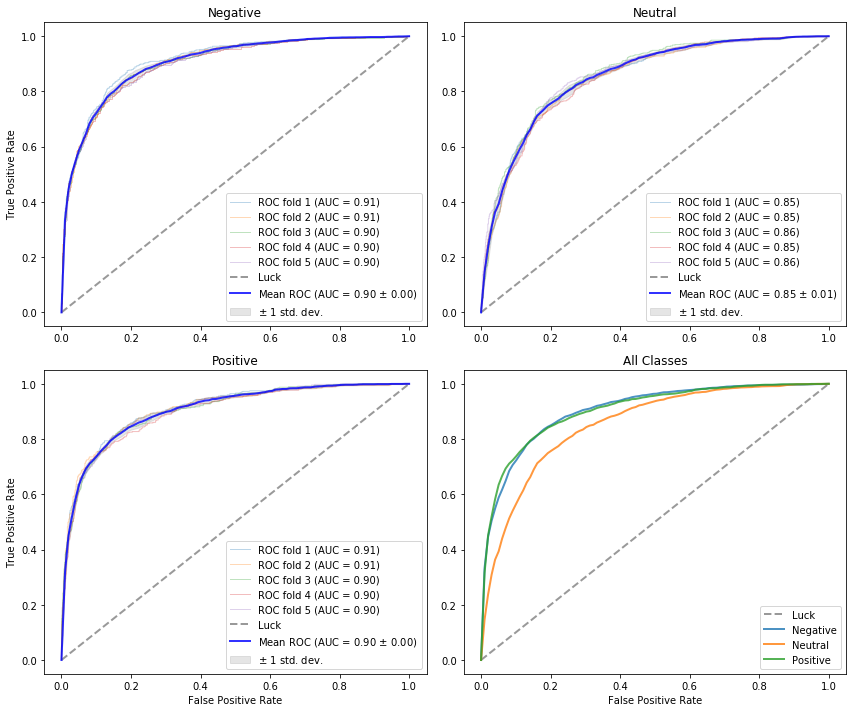
As a second diagnostic we generate a set of ROC curves, shown in the figure above. As before, a thorough explanation of ROC analysis is beyond the scope of this post (see Ch 8 in Data Science for Business for details). Panels A, B, and C show the performance of the classifier for each class in a one-vs-all fashion, indicating the model’s ability to distinguish that class from all others. Panel D overlays the mean ROC curves for each class. In comparing performance between classes, notice that the model exhibits a lower AUC value for the neutral class, compared with the others. This agrees with the observations from the confusion matrix—the model struggles to distinguish neutral tweets from the rest.
Considering the structure of our model, the observations above may not be too surprising: the distribution of words in neutral tweets may not distinguish it well from the other classes. For instance, a purely informational (neutral) tweet about a delay in service may share many of the same words as a (negative) complaint about someone’s delayed flight.
As a final qualitative evaluation of our model’s performance in the Caltrain domain, we used it to classify some recent Caltrain-related tweets.
Below are some tweets it classified as positive:
Shoutout to the cutest conductors on my 6:05 SB @Caltrain! Definitely made my morning with that sweet Halloween treat! #littlethings
— Catherine Tiffany (@catlalalaww) October 25, 2017
It’s been a rough day for @caltrain. Kudos to the Twitter team for keeping on it.
— Laura (@ContextSans) October 24, 2017
…some tweets it classified as negative:
@Caltrain the fact that my next best option after a 7:04 am train is a 7:49 train to sf is just ridiculous who makes your terrible schedule?
— Luke McCandless (@lukemccandless) October 26, 2017
Some @Caltrain delays…SB 226 combo'd up with 228 due to mech issues. NB 227 about 15 mins late…had to hold for a track trespasser.
— Mark Nieto (@TrafficmarkSF) October 23, 2017
…and some tweets it classified as Neutral:
262 -56 late @ SUN
366 -49 at MVW
264 -39 following 366
268 -39 at MPK
370 -28 following 268
272 -16 at SCS
376 -11 following 272#Caltrain— Caltrain (@Caltrain) October 26, 2017
@Caltrain a gaggle of teens who regularly ride on #nb263 blast offensive music on Bluetooth speakers, happens daily. What should riders do?
— Dr. Kayak Paddle (@AveyWatts) October 26, 2017
This is a reasonable baseline model, but there are multiple options for investigating possible improvements. For example, as mentioned in the introduction, we could improve the feature representation. We can investigate the types of errors made to prioritize these investigations.
Conclusion and Resources
Social media is a commonly consulted resource for commuters, and Caltrain riders are no different. As we’ve seen in this post, this means that a platform like Twitter can act as valuable source of signal for a sentiment classifier. In this context, a properly deployed model might help keep riders informed, and may even help Caltrain operations understand passenger reactions to delays.
Introductions to sentiment analysis include:
- Liu, Bing. Sentiment Analysis: Mining opinions, sentiments, and emotions. Cambridge University Press: 2015.
- Potts, Christopher. “Sentiment Symposium Tutorial.” Sentiment Analysis Symposium, San Francisco: November 8–9, 2011.
Aggarwal, C. C. and Zhai, C. “A Survey of Text Classification Algorithms.” In Aggarwal, Charu C. and Zhai, ChengXiang (Eds.), Mining Text Data, pp. 163–222. Springer: 2012.↩



