
Structured Streaming in Spark
This post gives you a quick overview of the new structured streaming feature in Spark 2.0, illustrating why it’s an exciting addition.
This post gives you a quick overview of the new structured streaming feature in Spark 2.0, illustrating why it’s an exciting addition.

While it would be great for everyone if you could just “buy a Hadoop” and skip straight to “Profit!”, in reality there’s a lot of work involved, and 95% of it is unique to your business. How do you determine the steps of a big data project, and ensure it delivers results early? This post talks about where to start.

A team of our data scientists recently won 2nd place in Confluent’s Kafka Hackathon. In this post, explore their project—streaming EEG data and visualizing it.
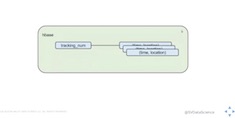
In this post, we cover what’s needed to understand user activity, and we look at some pipeline architectures that support this analysis.

This post walks you through a simple failure recovery mechanism, as well as a test harness that allows you to make sure this mechanism works as expected.
This month’s Throwback Thursday feature looks at some frequently asked questions about the role of the Chief Data Officer. An updated report will be forthcoming in September.

In this post we share some links to interesting work being done with social media data.

VP of Strategy Edd Dumbill was recently interviewed by James Haight on the Hadooponomics podcast. Find the audio and transcript here.
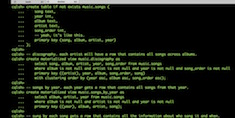
In this screencast, Principal Engineer and Cassandra committer Gary Dusbabek provides an overview of Materialized Views.