
Managing Uncertainty
Whatever Business You are in, Data is Your Business | November 30th, 2017
An aptitude for data is truly fundamental in today’s business world. Business moves fast, and technology moves even faster. In an ever-shifting landscape, how can you guide your business into managing the resulting uncertainty at the same time as tapping some of the growth potential?
Being data-driven is the best way to manage uncertainty—but achieving that is about far more than bringing a bunch of numbers to your latest meeting. It’s about having your entire organization set up in a way that can experiment itself in a competitive marketplace. At the end of the day, data and its associated technologies really drive business agility and allow us to discover and act upon market opportunity.
The technology is there to change our mindset, and the move to promoting data as ubiquitous is one of the hallmarks of data-driven organizations. But we also need to think about how we’ll manage that technology, as it doesn’t work the same way it used to.
Let’s look at a couple of the qualitative changes that innovative companies are taking advantage of—changes that you too can embrace in order to make your business more data-driven.
Changing the Way We Think About Systems
Technologies such as Hadoop and Spark have a different nature of scaling than those that came before them. They roughly scale linearly with demand, instead of hitting an elbow of prohibitive cost where we simply can’t buy a server big enough, or can’t afford the licensing cost for our database. Instead, when we need to scale modern database technologies, we simply add to the cluster and we can scale out.
Scale-out systems move us from a world of managing scarcity to promoting utility. If you’re involved in data management, then you’ve recognized that your role is changing: everyone is becoming more data-aware and demanding more from you. You can transition from being guardians of resource to being evangelists of data—providing access to data so that creative and strategic uses can take off.
The chart below is one way of thinking about new systems.
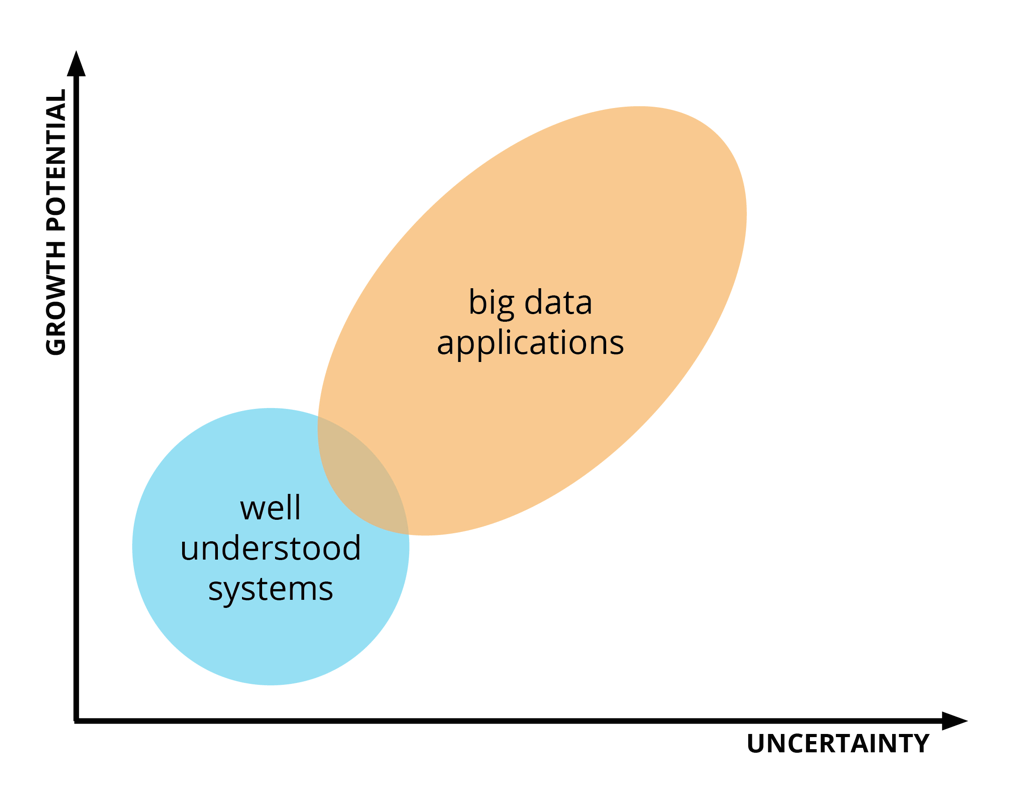
In the blue circle, we have the well understood systems that we know about. This includes our customer database and data warehouses—things that over the last couple of decades we’ve come to know and understand the dynamics of. The orange circle is the area of potential, with new applications that use structured data and scale-up technologies.
The key to bridging the gap between these two areas is being open to experimentation. In this sense, startups are machines for exploring opportunities, seeing which ones work in the market, and doubling down on them.
Experimenting for Success
When we talk about experimenting, we don’t mean a mad scientist with bubbling test tubes and clouds of green smoke. Rather, experimentation is a way of navigating and discovering the unknown in a structured way. It’s about learning what doesn’t work as much as it is about learning what does. For every successful, groundbreaking paper, there are thousands of negative results that never get published. It’s important to recognize that, and to be okay with it.
To use experimentation successfully, you must adhere to a few requirements.
First, experimentation must be cheap, because failure is an innate piece of the process. We need to be able to rattle off experiments, many of them a day if possible. If you ask your team what have they done that has failed, and they have no answer, then they shouldn’t be getting their bonus. Discovering what doesn’t work helps us map the landscape, and enables us to ask good questions.
Because you must be able to iterate, experiments should also be quick. If you give me up-to-the-minute data about my customers, but I can’t change my product any sooner than a six-month cycle, then it doesn’t really benefit me to have that real-time data. Combining that data with the ability to change the product in real-time is what gives me the advantage.
Lastly, experiments shouldn’t break things. Our operational systems should be available as building blocks for innovation in a way that still maintains service levels. Fortunately, there are ways to ensure this—through APIs, building platforms, and simulations.
I’ve written about the Experimental Enterprise before, but it’s worth a reminder now. Many trends coming out of IT in the last ten years combine to create data-driven companies. You may have heard of each building block in the graphic below individually as buzzwords, but what matters is how they work together.
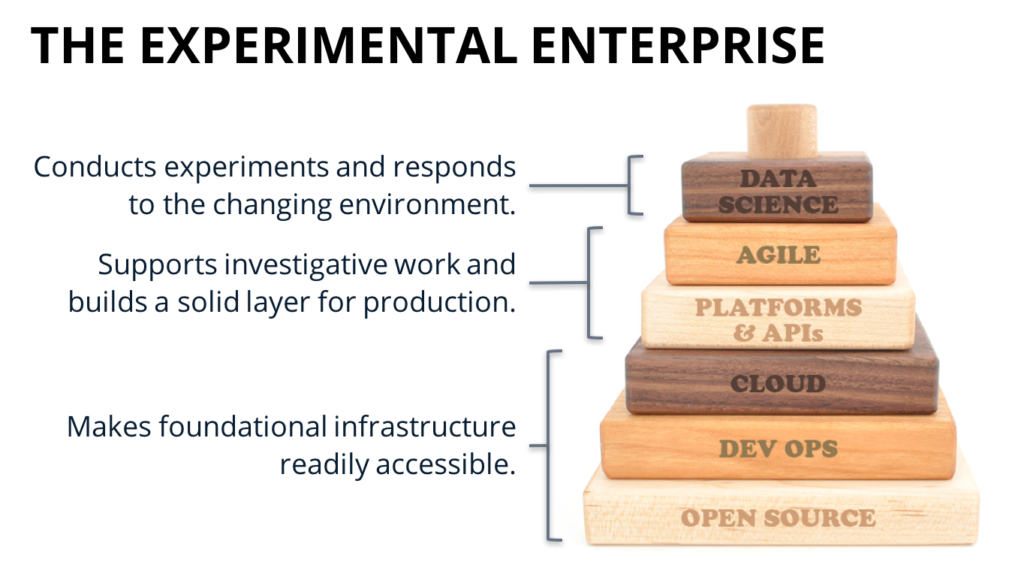
In the bottom layer, we have infrastructure that is now readily available in ways it wasn’t before. Open source gives any developer access to a hardened, enterprise-ready database in a matter of minutes. Previously, developers in some companies had to wait three months to get a license—being able to spin up a database instantly is a game-changer.
On top of that sits the practice of DevOps, which is about programmable infrastructure. It’s one thing to be able to get a new database instantly, but what about a new database configured in the same way as your production database? Or what about a virtual machine that considers all your auditing and logging requirements? DevOps enables us to do those things; it also enables us to deploy new versions of our software or our models into production very quickly, so we can run tens of experiments per day.
The cloud lets us have this infrastructure at the push of a button. A lot of the things we do today in data science aren’t totally new—the difference is that, ten years ago, only rich corporations like Walmart could afford to do them, and now we all can. Rather than needing to buy 2,000 computers to crunch your data and find patterns, you can now enter a credit card into Amazon and use theirs. The availability of the cloud enables much more experimentation with much less overhead, and allows us to uncover hidden value in our data.
The availability of platforms and APIs enables us to navigate that unknown space between the blue and orange circles, and to manage uncertainty by enabling us to use an agile development approach. This means that we can check in periodically, iterate on an idea, and drive towards where we want to go as a business even if that requires a pivot to get there. This is how we really manage risk as we investigate.
And finally, data science gives us insight that we can use to make better decisions. It is what allows us to develop and test hypotheses until we hit on the next big thing.
Any business that is data-driven has all these components, as well as an attitude geared towards using data to drive business value.
Conclusion
Experimentation is not a linear march of victory toward inevitable glory. Instead, it’s a tedious process where you incrementally learn, poke at, and try different things until you hit on something that actually works for your business.
In that vein, you need to be able to work in a way that regularly checks the business and reports back. For us, that means reporting back every two weeks, incorporating understanding from the business, checking in with what we’ve discovered, and having our experiments tied to things that create value.
A few other ways we work to manage uncertainty for our clients:
- We look for best practices in the Valley—whether it’s version control, Jupyter Notebooks, or using scale-out systems—and how we can adapt those for an enterprise setting.
- We use an agile approach so that we can move as quickly as possible, without accidentally driving right off the end of a cliff.
- We emphasize over and over the importance of being oriented towards business value, rather than towards technology for technology’s sake.
How do you manage uncertainty in your organization? Leave us a comment and let us know.



