
Two Tips for Optimizing Hive
March 5th, 2015
NOTE: This guest post appears courtesy of Qubole. Gil Allouche, until recently the Vice President of Marketing at Qubole, began his marketing career as a product strategist at SAP while earning his MBA at Babson College. He is a former software engineer.
Hadoop is only beneficial if using it is efficient. Hadoop’s Apache Hive is frequently used to handle ad-hoc queries and regular ETL workloads. While it is one of the more mature solutions in the Hadoop ecosystem, the majority of data scientists and engineers are still learning how to use the tool more efficiently. At Qubole, our customers have been able to reduce costs and improve efficiency by using certain techniques when performing data layout and sampling in Hive.
DataXu, a data and analytics platform for marketers that features an automated learning system that helps marketers identify and engage the best prospects, frequently runs ad-hoc queries for its clients. By optimizing its Hive processing, it was able to run faster queries and split computations to better meet consumer demand.
This blog post will go over two techniques engineers can follow in order to optimize Hive and more efficiently reach their business goals.
Partitioning Hive Tables
Hive is frequently used to query larger tables and run queries that require full-table scans. Since Hadoop’s Hive tables are linked to directories on a data storage service, such as Amazon S3, Hive reads all of the data stored in the directory and applies query filters as it goes through the data. This process can quickly take up unnecessary time and resources since the full table scan is repeated for every new query. However, once an engineer has worked with a data-set for a while, they will have a working knowledge of which data queries are frequently scheduled and will be able to identify common data structures used in those regular queries. For example, an airline may frequently analyze data based on flight origin state.
In order to improve query performance, an engineer can then use partitioning to help Hive focus solely on the data that is important. Partitioning a table stores data in sub-directories categorized by table location, which allows Hive to exclude unnecessary data from queries without reading all the data every time a new query is made. For example, if the airline mentioned above wanted to partition data based on origin state, it would define the state column as a partition as it was creating the Hive table. Then, as data is written to the table, it will be written to sub-directories named by the state abbreviations. Then, a query can be entered “SELECT * FROM Airline_Bookings_All WHERE origin_state = ‘CA’ to skip any sub-directory that doesn’t have data with an origin state of California.
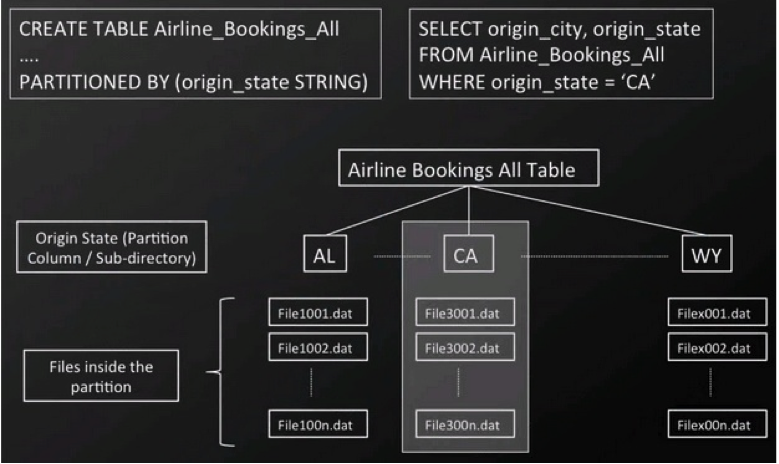
When partitioning tables, engineers should pay special attention to how they select the partition key, which should always be a low cardinal attribute, such as using dates for the key if you are working with a time dimension. Similarly, hierarchical positions, such as country, work well if your data is associated with location. Using an attribute that fragments the data too much, such as an airline partitioning by itinerary ID, makes it difficult to analyze the data from different perspectives without re-doing the process.
While partitioning is a great technique to improve performance by distributing data, it also requires a careful review of the number of partitions and frequency of partition additions/deletions. Creating partitions in the scale of 10’s of thousands should be avoided unless there is a very strong reason.
Bucketing Hive Tables
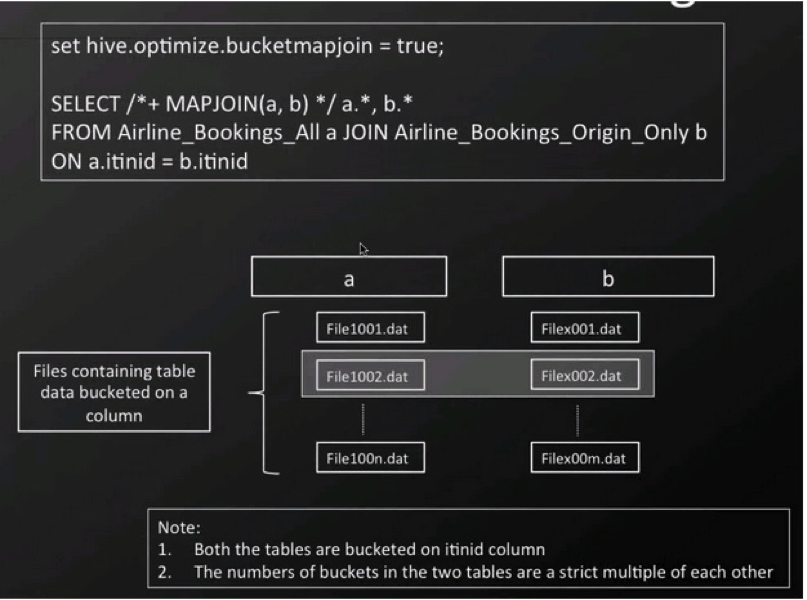
While it would be inefficient to use partitioning to segment an airline’s data by itinerary ID, this type of data is frequently used in join operations. Joins can be optimized by bucketing “similar” IDs with the goal of minimizing processing steps. The word similar was placed in quotes because data sets like itinerary ID’s have no real similarity, but the goal would be to place the same IDs from two tables in the same processing bucket. This process is completed by hashing the data and then storing it by hash results. Bucketing will then improve join performance if the bucket and join keys are common.
Before writing data to the bucketed table, be sure to set the bucketing flag “SET hive.enforce.bucketing=true;” In order to leverage bucketing in a join operation, use the code “SET hive.optimize.bucketmapjoin=true.” This setting will let Hive know to perform bucket level join during the map stage join and will reduce the scan cycles required to locate a specific key since bucketing will place the key in a particular bucket.
A few points to remember- bucketing only helps when the join key and bucketing key are the same. Also, if your data is volatile and you continue to add files after creating buckets, you lose the advantage of bucketing.
There are many more best practices for using Apache Hive, but the tips described above can be easily used by anyone using Hive to boost query speeds and save resources. Keep in mind that there are always some limits to each optimization technique depending on the use case and type of data, and there are of course, multiple tools that work with Hadoop that may offer faster queries depending on the workload.
If you are getting started with a big data project and are looking for expert advice, this slideshare features tips from industry experts on how to be successful with a big data initiative.
Read more from Qubole, including tips from our own leaders at SVDS, in their recent series of Expert Big Data Tips.
Header image by Emilian Robert Vicol. Used under CC BY 2.0.



