Previous Article
Leading Investment Management Firm — High-Performance Data Architecture

Summary
A top-five global investment management firm needed increased reliability, read/write access, and usability for risk data.
Silicon Valley Data Science designed and tested a more efficient, scalable next-generation architecture to support the needs of future data growth and business demand.
Background and Business Problem
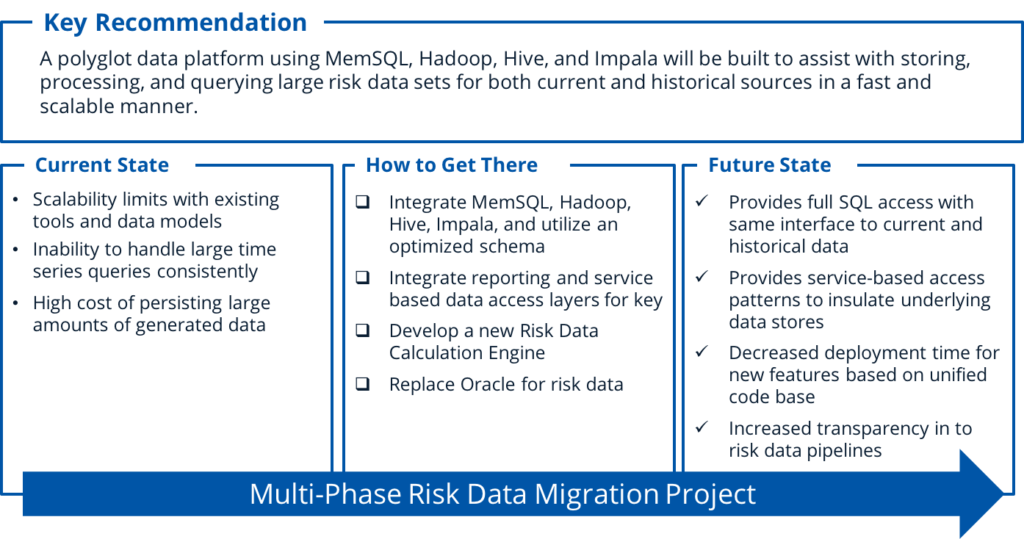
SVDS was engaged by a top-five investment management firm to assist with migrating from MapR to a Cloudera-based platform, designed to enable increased reliability, read/write access, and usability for risk data.
The client generates significant amounts of data each day, which must be stored and made available to a wide variety of tools and downstream systems. Data is being pulled daily into a custom-built in-memory structure that enables users to write user-defined functions (UDFs) and generate their own metrics on demand. Roughly 10,000 additional metrics are generated for users from this system. Legacy workloads are entirely hosted in Oracle, with dedicated specialized hardware. Despite optimized hardware, the legacy systems were no longer scalable.
Prior to our engagement, the client had begun the process of moving data storage and processing to MapR. While initial results were promising, certain design aspects and lack of support for critical components in the Hadoop ecosystem ultimately led them to seek alternatives to MapR.
Solution
SVDS worked with the client’s lead technical architects to identify critical architectural considerations, and develop a vision for how the architecture could be transformed. In order to manage delivery risk and build confidence in the viability of proposed solutions, we prototyped a number of new approaches to existing workloads.
We evaluated and performance tested multiple data storage, processing, and query components to ensure that key performance requirements were met. This involved reviewing not just Hadoop-based query stores, but also memory based stores such as MemSQL, and cloud based tools such as BigQuery, RedShift, and Azure SQL Data Warehouse.
Our efforts resulted in a successful migration of ~400 TB of risk data, and set the foundation for easier, performant, and more consistent usage of risk data throughout the organization.
Our client then used the patterns we established to migrate all workloads from Oracle and MapR to a Cloudera based Oracle Big Data Appliance, utilizing Spark, Impala, Hive, and the other tools in the Hadoop ecosystem.