
Easily Spinning up Data Platforms
A quick overview of the motivation behind our instant and repeatable data platform tool.
Mark has extensive experience architecting and implementing data science solutions across a variety of industries. His passion is Data Plumbing, where Data Science meets the real world of DevOps and Infrastructure Engineering.
A quick overview of the motivation behind our instant and repeatable data platform tool.
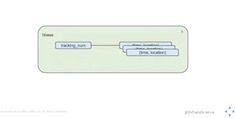
In this post, we cover what’s needed to understand user activity, and we look at some pipeline architectures that support this analysis.

Rather than get bitten by the idiosyncrasies involved in running Spark on YARN vs. standalone when you go to deploy, here’s a way to set up a development environment for Spark that more closely mimics how it’s used in the wild.
Enterprise Data World focuses on data-driven business. Several of us will be there this year, talking about data platforms and enterprise data science. Let us know if you’ll be there, or you can sign up to receive our slides.
Join us as CTO John Akred gives a talk on alternative approaches to valuing data within an organization, and Data Scientist Chloe Mawer demonstrates the power of Jupyter notebooks using a real-world train-detection problem. We’ll also present a tutorial on building data pipelines with Kafka and Spark.
Principal Engineer Mark Mims will be speaking at this online conference, presenting on how to identify user activity from streams.
Join CTO John Akred for a talk on Running Agile Data Science Teams, and VP of Engineering Stephen O’Sullivan for a talk on Choosing an HDFS data storage format (Avro vs. Parquet). Principal Engineer Mark Mims will hold Office Hours.