
Models: From the Lab to the Factory
March 15th, 2017
In our industry, much focus is placed on developing analytical models to answer key business questions and predict customer behavior. However, what happens when data scientists are done developing their model and need to deploy it so that it can be used by the larger organization?
Deploying a model without a rigorous process in place has consequences—take a look at the following example in financial services.
With its high-frequency trading algorithms Knight was the largest trader in U.S. equities, with a market share of 17.3% on NYSE and 16.9% on NASDAQ. Due to a computer trading “glitch” in 2012, it took a $440M loss in less than an hour. The company was acquired by the end of the year. This illustrates the perils of deploying models to production that are not properly tested and the impact of the bugs that could sneak through.
In this post, we’ll go over techniques to avoid these scenarios through the process of model management and deployment. Here are some of the questions we have to tackle when we want to deploy models to production:
- How do the model results get to the hands of the decision makers or applications that benefit from this analysis?
- Can the model run automatically without issues and how does it recover from failure?
- What happens if the model becomes stale because it was trained on historical data that is no longer relevant?
- How do you deploy and manage new versions of that model without breaking downstream consumers?
It helps to see data science development and deployment as two distinct processes that are part of a larger model life cycle workflow. The example diagram below illustrates what this process looks like.
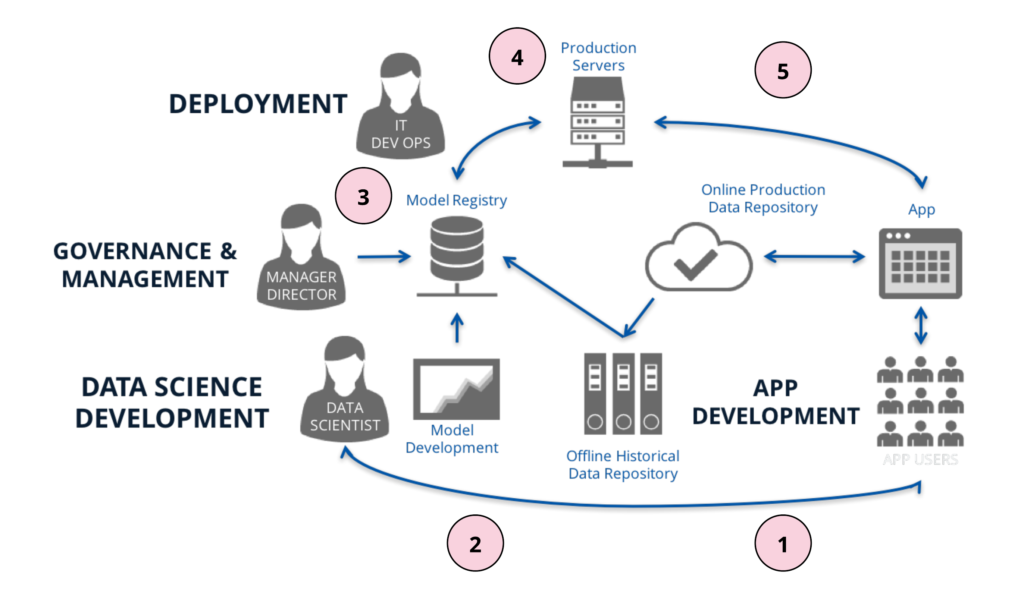
- We have end-users interacting with an application, creating data that gets stored in the app’s online production data repository.
- This data is later fed to an offline historical data repository (like Hadoop or S3) so that it can be analyzed by data scientists to understand how users are interacting with the app. It can also be used, for example, to build a model to cluster the users into segments based on their behavior in the application so we can market to them with this information.
- Once a model has been developed, we’ll want to register it in a model registry to allow a governance process to take place where a model is reviewed and approved for production use, and requirements can be assessed for deployment.
- Once the model has been approved for production use, we need to deploy it. To do this, we need to understand how the model is consumed in the organization and make changes to support this, ensure the model can run end to end automatically within specified performance constraints, and that there are tests in place to ensure that the model deployed is the same as the model developed. Once these steps are done, the model is reviewed and approved again prior to going live.
- Finally, once the model is deployed, the predictions from this model are served to the application where metrics on the predictions can be collected based on user interaction. This information can serve to improve the model or to ask a new business question which brings us back to (2).
In order to make the life cycle successful, it is important to understand that data science development and deployment have different requirements that need to be satisfied. This is why you need a lab and a factory.
The lab
The data lab is an environment for exploration for data scientists, divorced from application’s production concerns. We may have an eventual end goal of being able to use data to drive decision making within the organization, but before we can get there, we need to understand which hypotheses make sense for our organization and prove out their value. Thus we are mainly focused on creating an environment—“the lab”—where data scientists can ask questions, build models, and experiment with data.
This process is largely iterative, as shown in the diagram below based on the CRISP-DM model.
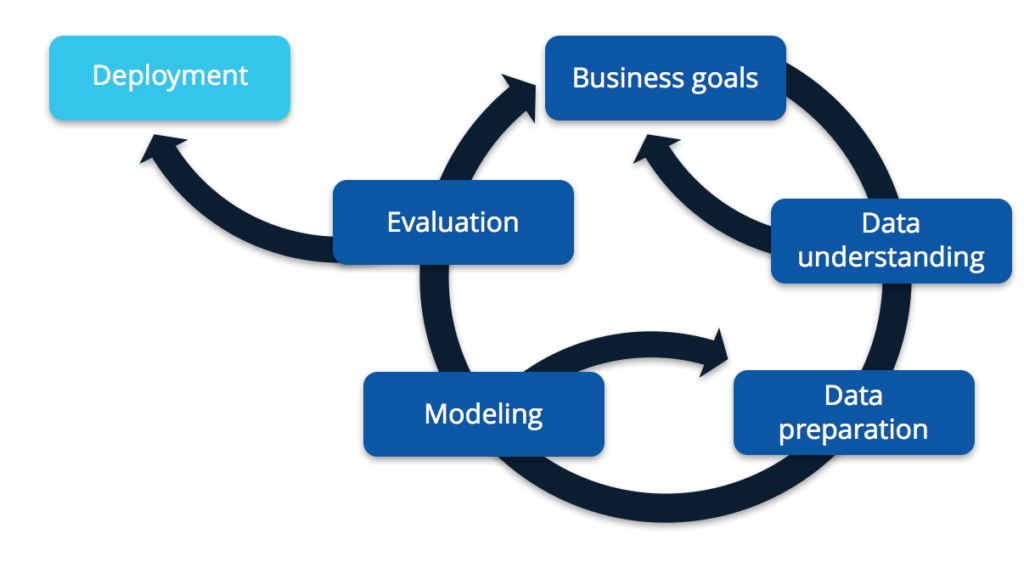
We will not go into too much detail in this post, but we do have a tutorial that goes in depth on this topic. If you’d like to download the slides for that tutorial, you can do so on our Enterprise Data World 2017 page.
What concerns us here is that we need a lab to enable exploration and development of models, but we also need a factory when we need to deploy that model to apply it to live data automatically, deliver results to the appropriate consumers within defined constraints, and monitor the process in case of failure or anomalies.
The factory
In the factory we want to optimize value creation and reduce cost, valuing stability and structure over flexibility to ensure results are delivered to the right consumers within defined constraints and failures are monitored and managed. We need to provide a structure to the model so that we can have expectations on its behavior in production.
To understand the factory, we’ll look at how models can be managed via the model registry and what to consider when undergoing deployment.
Model registry
To provide a structure to the model, we define it based on its components—data dependencies, scripts, configurations, and documentation. Additionally, we capture metadata on the model and its versions to provide additional business context and model-specific information. By providing a structure to the model, we can then keep inventory of our models in the model registry, including different model versions and associated results which are fed by the execution process. The diagram below illustrates this concept.
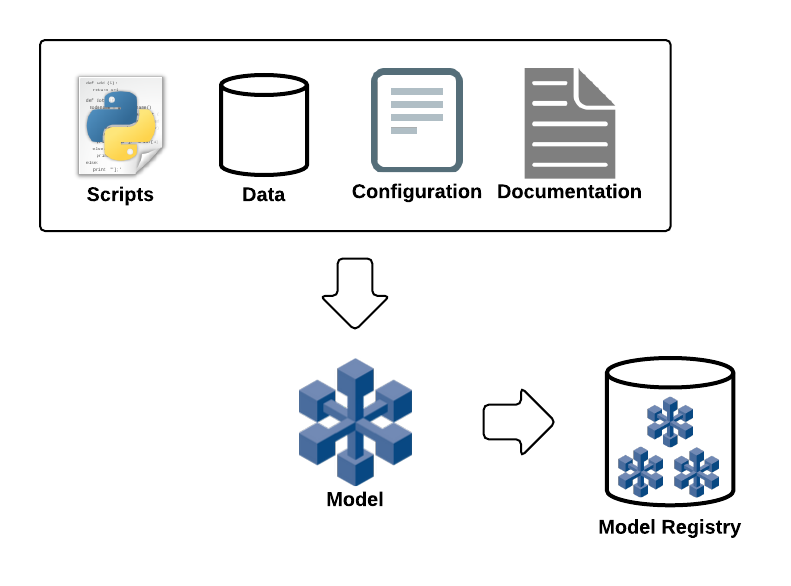
From the registry, we can:
- Understand and control which version of a model is in production.
- Review the release notes that explain what has changed in a particular version.
- Review the assets and documentation associated with the model, useful when needing to create a new version of an existing model or perform maintenance.
- Monitor performance metrics on model execution and what processes are consuming it. This information is provided by the model execution process, which sends metrics back to the registry.
You can also choose to include a Jupyter Notebook with a model version. This allows a reviewer or developer to walk through the thought process and assumptions made by the original developer of the model version. This helps support model maintenance and discovery for an organization.
Here is a matrix decomposing the different elements of a model from our work in the field:
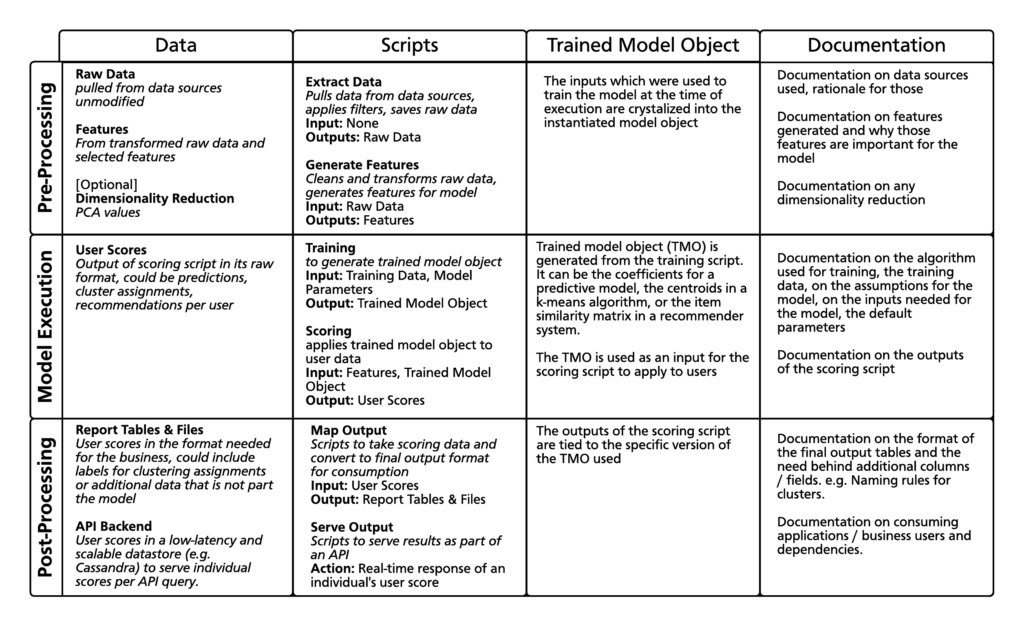
The registry needs to capture the associations between data, scripts, trained model objects, and documentation for particular versions of a model illustrated in the figure.
What does this give us in practice?
- By collecting the required assets and metadata on how to run a model, we can drive an execution workflow, which will apply a particular version of that model to live data to generate predictions to the end user. If it’s part of a batch process, we can use this information to create transient execution environments for the model to pull the data, pull the scripts, run the model, store the results in object storage, and spin down the environment when the process is complete, maximizing resources and minimizing cost.
- From a governance perspective, we can support business workflows that decide when models get pushed to production and allow for ongoing model monitoring to, for example, make decisions as to whether the model should be retrained if we’ve identified that the predictions are no longer in line with the actuals. If you have auditing requirements, you may need to explain how you produced a particular result for a customer. To do this, you would need to be able to track the specific version of the model that was run at a given time and what data was used for it to be able to reproduce the result.
- If we detect a bug in an existing model, we can mark that version as “should not be used” and publish a new version of the model with the fix. By notifying all of the consumers of the buggy model, they can transition to using the fixed version of the model.
In the absence of these steps, we run the risk that model maintenance becomes a challenging process of trying to understand the intentions of the original developer, models deployed to production which no longer match those in development producing incorrect results, and disrupting downstream consumers when an existing model is updated.
Model deployment
Once a model has been approved for deployment, we need to go through steps to ensure the model can be deployed. There should be tests in place to verify correctness, the pipeline of extracting raw data, feature generation, and model scoring should be analyzed to make sure that model execution can run automatically, will expose results in the way needed by consumers, and meets the performance requirements defined by the business. Also ensure that model execution is monitored in case of errors or if a model has gone stale and is no longer producing accurate results.
Prior to deployment, we want to ensure that we test the following:
- Whether the model deployed matches the expectations of the original model developer. By using a test input set identified during development which produces validated results, we can verify that the code being deployed is matching what was expected during development. We illustrated the need for this in a previous blog post.
- Whether the model being deployed is robust to a variety of different inputs, testing extremes of those outputs and potentially missing values due to data quality issues. The model should have controls in place to prevent these inputs from crashing the model and, in effect, affecting its downstream consumers.
We minimize the risk that the model deployed matches the model developed by 1) running tests prior to deploying the model to production, and 2) capturing the environment specifics such as specific language versions and library dependencies for the model (e.g. a Python requirements.txt file).
Once deployed in production, we want to expose the predictions of the model to consumers. How many users will be consuming this model prediction? How quickly must the feature data be available when scoring the model? For example, in the case of fraud detection, if features are generated every 24 hours, there may be that much lag between when the event happened and when the fraud detection model detected the event. These are some of the scalability and performance questions that need to be answered.
In the case of an application, ideally, we want to expose the results of the model via a web service, either via real-time scoring of the model or by exposing scores that were produced offline via a batch process. Alternatively, the model may need to support a business process and we need to place the results of the model in a location where a report can be created for decision makers to act on these results. In either case, without a model registry, it can be challenging to understand where to find and consume the results of a current model running in production.
Another use case is wanting to understand how the model is performing against live data in order to see whether the model has gone stale or whether a newly developed model outperforms the old one. An easy example of this is a regression model where we can compare the predicted vs actual values. If we do not monitor the results of a model over time, we may be making decisions based on historical data that is no longer applicable to the current situation.
Conclusion
In this post, we walked through the model life cycle, and discussed the needs of the lab and the factory, with the intent to reduce the risk of deploying “bad” models that could impact business decisions (and potentially incur a large cost). In addition, the registry provides transparency and discoverability of models in the organization. This facilitates new model development by exposing existing techniques used in the organization to solve similar problems and facilitates existing model maintenance or enhancements by making it clear which model version is currently in production, what are its associated assets, and a process to publish a new model version to consume.
Here at SVDS, we are developing an architecture that supports onboarding of models and their versions into a registry, and manages how those model versions are deployed to an execution engine. If you’d like to hear more about this work, please reach out.
Editor’s note: Mauricio (as well as other members of SVDS) spoke at TDWI Accelerate in Boston. Find more information, and sign up to receive our slides here.
sign up for our newsletter to stay in touch