DeepDream: Accelerating Deep Learning With Hardware
March 29th, 2017
Editor’s note: This was originally posted on Medium by Matthew Rubashkin
The exciting DeepGramAI Hackathon just concluded, and I wanted to share some of the cool things John Henning and myself built this weekend! Other cool projects at the Hackathon ranged from a speech to math decoder, to a semantic parser for image segmentation, and the winning project by Jeff Lam—a deep learning network for reading minds with Keras and EEG data.
My goal for this hackathon was to live process and augment video via DeepDream image generation. This project would have application in augmented reality gaming or live-processing of videos with DeepDream features.
Using consumer hardware, it takes ~45 to 90 seconds to process a single image with TensorFlow DeepDream on CPU alone, and ~5–30 seconds utilizing a graphical processing unit (GPU). In order to accelerate image processing to >15 frames per second, we first benchmarked the effect of different hardware components on DeepDream performance.
Benchmarking DeepDream
We first compared performance of DeepDream on processing a single image, using TensorFlow 1.01 in Python (code found here):
- Model: Inception 5h
- Extract Layer: mixed4d_3x3_bottleneck_pre_relu
- Parameters: t_obj_filter= 139 , iter_n=10, step=1.5, octave_n=4, octave_scale=1.4
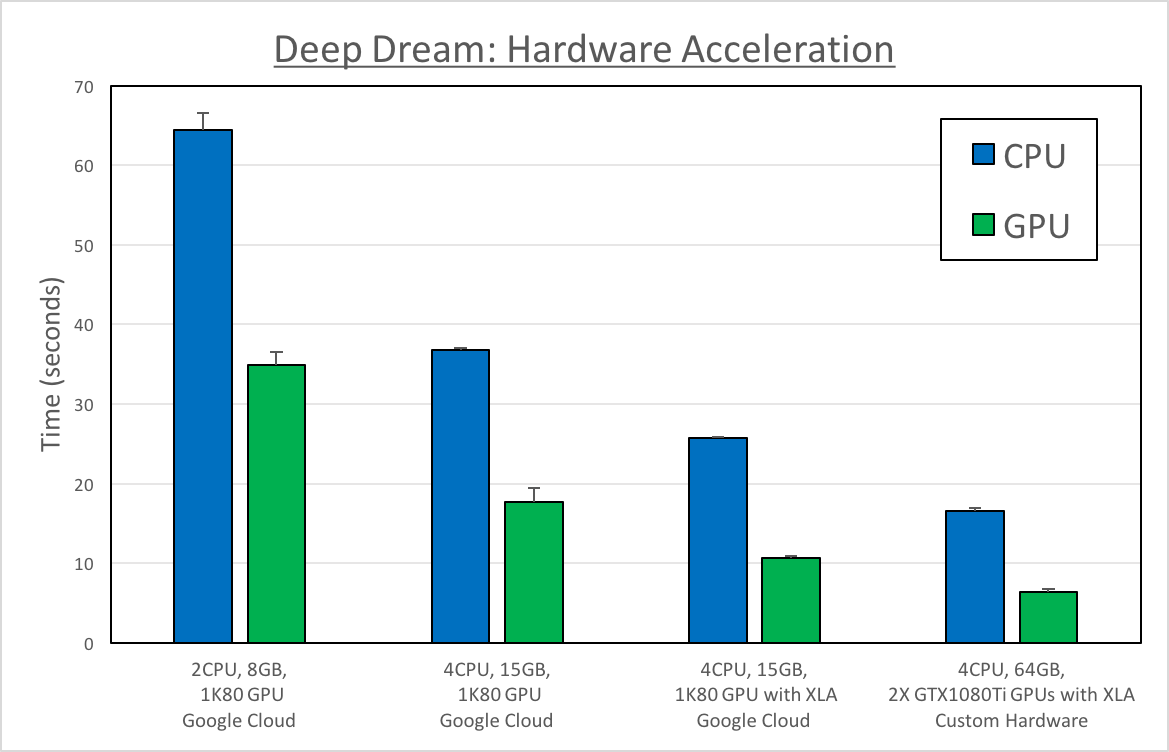
Our original test was on the Google Cloud Platform (GCP) using an n1-standard-2 instance with 2CPU, 8GB of memory and 1 NVIDIA K80 GPU. All tests used NVIDIA parallel computing platform CUDA, as well as the CUDA® Deep Neural Network library (cuDNN). In the blue columns you can see that with CPU only, it took longer than 1 minute to process a single image. As expected, using a K80 GPU on the n1-standard-2 instance speed up processing. With this configuration it took ~30 seconds to process a single image. We were then able to accelerate this performance to less than 20 seconds using a larger instance type, the n1-standard-4 that comes with 4 CPUs, 15 GB RAM and the same NVIDIA K80 GPU.
We next tested if TensorFlow’s new Acceleration Linear Algebra (XLA) compiler would increase performance. To do this, we compiled the TensorFlow r1.0 branch from source with the XLA and CUDA options on the n1-standard-4 instance. I was not sure what to expect, and was pleasantly surprised that with the GPU we were able to process an image in ~10 seconds (~60% increase in speed with XLA).
Our last step was using our own custom hardware with 4 cores, 64GB RAM, and running two of the new 1080Ti NVIDIA GPU Cards. This rig was built by my coworkers at Silicon Valley Data Science (SVDS), Paul Ho and Jeff Lam. I would definitely recommend you reach out to these hardware magicians if you have any questions about setting up your own multi-GPU hardware! Below is a picture of the machine with 3 cards installed (our test was run with the two 1080Ti cards with the SLI bridge).

Using our custom hardware with XLA enabled, we observed processing of single images in 6.5 seconds, a significant improvement! In the future we plan to repeat our multi-GPU test on GCP and Amazon Web Services (AWS) to confirm our findings on our custom hardware.
Adjusting DeepDream Parameters
After we explored how scaling hardware could accelerate processing, we next explored how changing parameters in the DeepDream algorithm could change speed and output image quality. To do this, we wrapped the render_deepdream function provided in the TensorFlow examples folder. We chose several parameters to experiment with including the object filter from the mixed4d_3x3_bottleneck_pre_relu layer, processing iterations per image, number of image scales to be analyzed (octaves), and the relative size of the features (octave scale).
# Set parameters for generating different images
parameters = [
{'name': uuid.uuid4(), 't_obj_filter': 139, 'img0': img0, 'iter_n':10, 'step':1.5, 'octave_n':4, 'octave_scale':1.4},
{'name': uuid.uuid4(), 't_obj_filter': 139, 'img0': img0, 'iter_n':10, 'step':1.5, 'octave_n':4, 'octave_scale':1.0}, ]
output_data={}
# Iterate through all parameters and track performance
for i in range(0,len(parameters)):
start_time=time.time()
# Perform the deep dream rendering and store output array, which is called output_image
output_image=render_deepdream(T(layer)[:,:,:,parameters[i]['t_obj_filter']],
img0=parameters[i]['img0'],
iter_n=parameters[i]['iter_n'],
step=parameters[i]['step'],
octave_n=parameters[i]['octave_n'],
octave_scale=parameters[i]['octave_scale'],
show_image=False)
# Log the output as a dictionary of tuples, including the image, timing and original parameters
end_time=time.time()
output_data[str(parameters[i]['name'])]=(output_image.copy(), end_time-start_time, parameters[i])
We found that decreasing iteration and octave number reduces processing time while reducing image quality. At 5 iterations and 1 octave our processing time dropped to ~2.5 seconds, but our images’ DeepDream features were noticeably less expressive. While that finding was expected, we did not find that processing time was changed by t_obj_filter number. I have included examples outputs below to demonstrate the variety of images that can be generated while holding all parameters except for t_obj_filter constant:

iOS Application to Serve DeepDream Image Generation
On Sunday morning of the 48hr Deep Learning Hackathon we realized that we did not have the working time (or GCP quota) to provision a Google Cloud Platform instance with 8 K80 GPUs to accelerate our image processing for streaming video. For this reason, we pivoted to creating a small iOS app as an endpoint for serving our DeepDream model on our n1-standard4 GCP instance.
We first modified our DeepDream Python script to enable serving of the model. This was accomplished by creating a custom DeepDream Python class. This class had functionality for persisting the inception v5 graph in memory, and making function calls to process an image with given parameters. Below, our screenshots of our LiveDream app running on my iPhone SE:
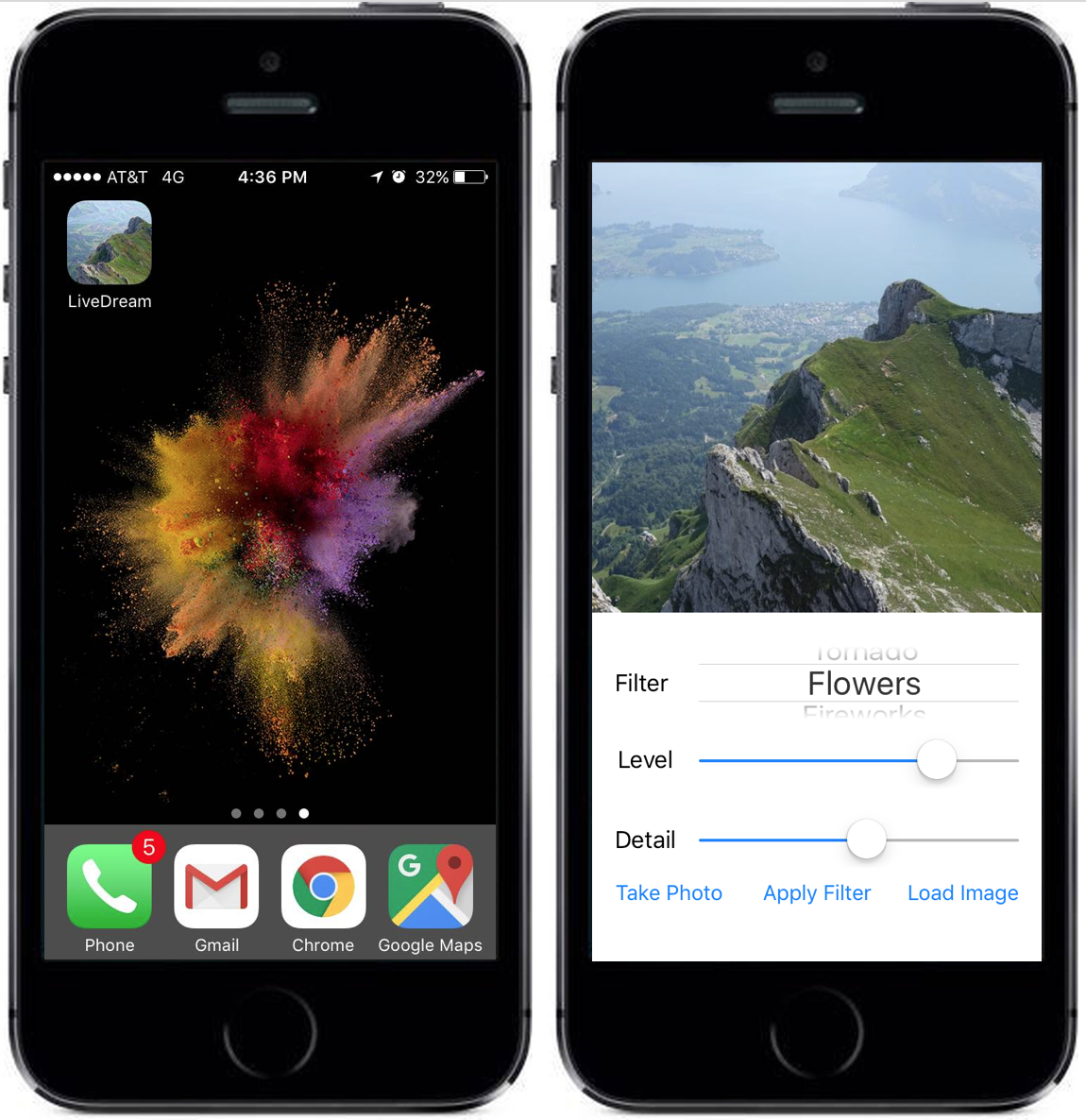
The application allows the selection of:
- Filter: Selection of our favorite DeepDream filters in the 4d layer
- Level: Iterations DeepDream would run on the image
- Detail: Scales of the image to be analyzed (octaves)
Example DeepDream results from our GCP K80 enabled server are shown below:

Future Steps
The Deep Learning Hackathon was a great opportunity to explore how to accelerate DeepDream processing, and we look forward towards improving DeepDream live stream processing in the future! Here are several things we will continue to iterate on:
- Change the weights from float32 to float16 or int to reduce model size
- Use an earlier Inception layer to reduce total operations
- Load up more GPUs onto a single machine on GCP or AWS
- Utilize different models such as SqueezeNet (~5MB) that are not as large as Inception-5h (~48MB).
If you have any questions how we performed our benchmarking, or suggestions for improvements, please reach out in the comments or at our GitHub Repository.
sign up for our newsletter to stay in touch