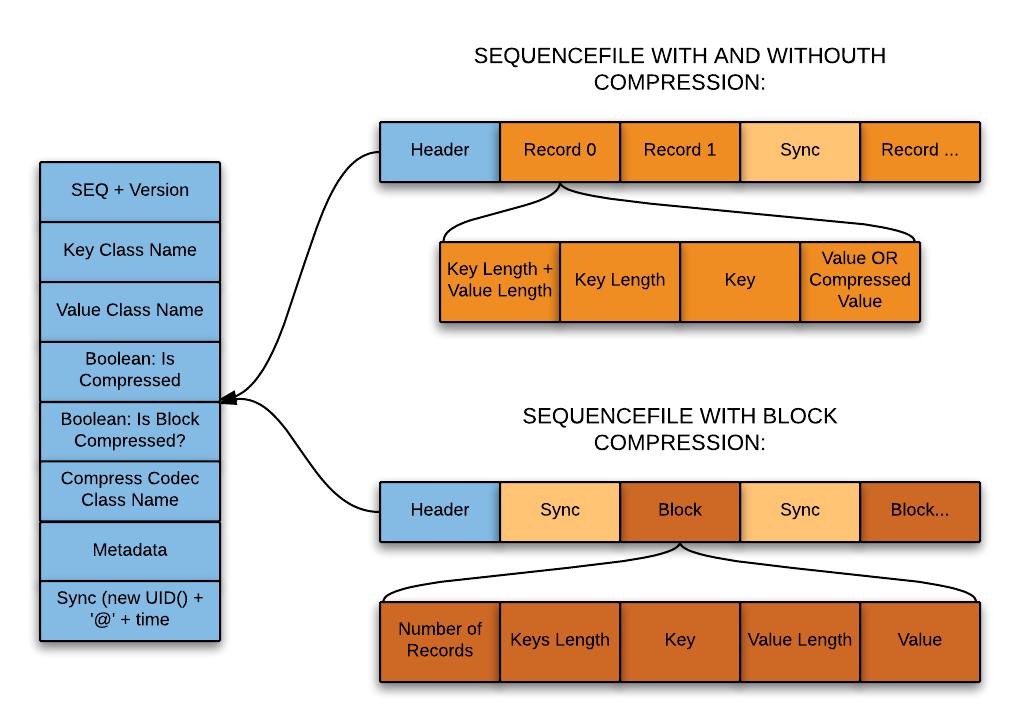
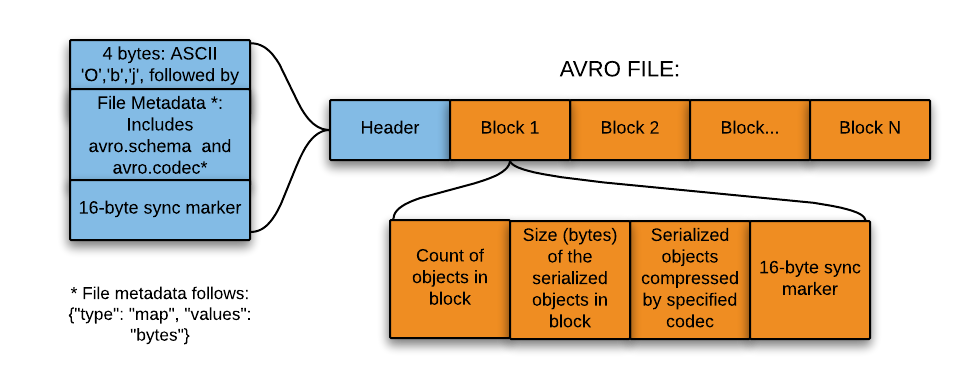
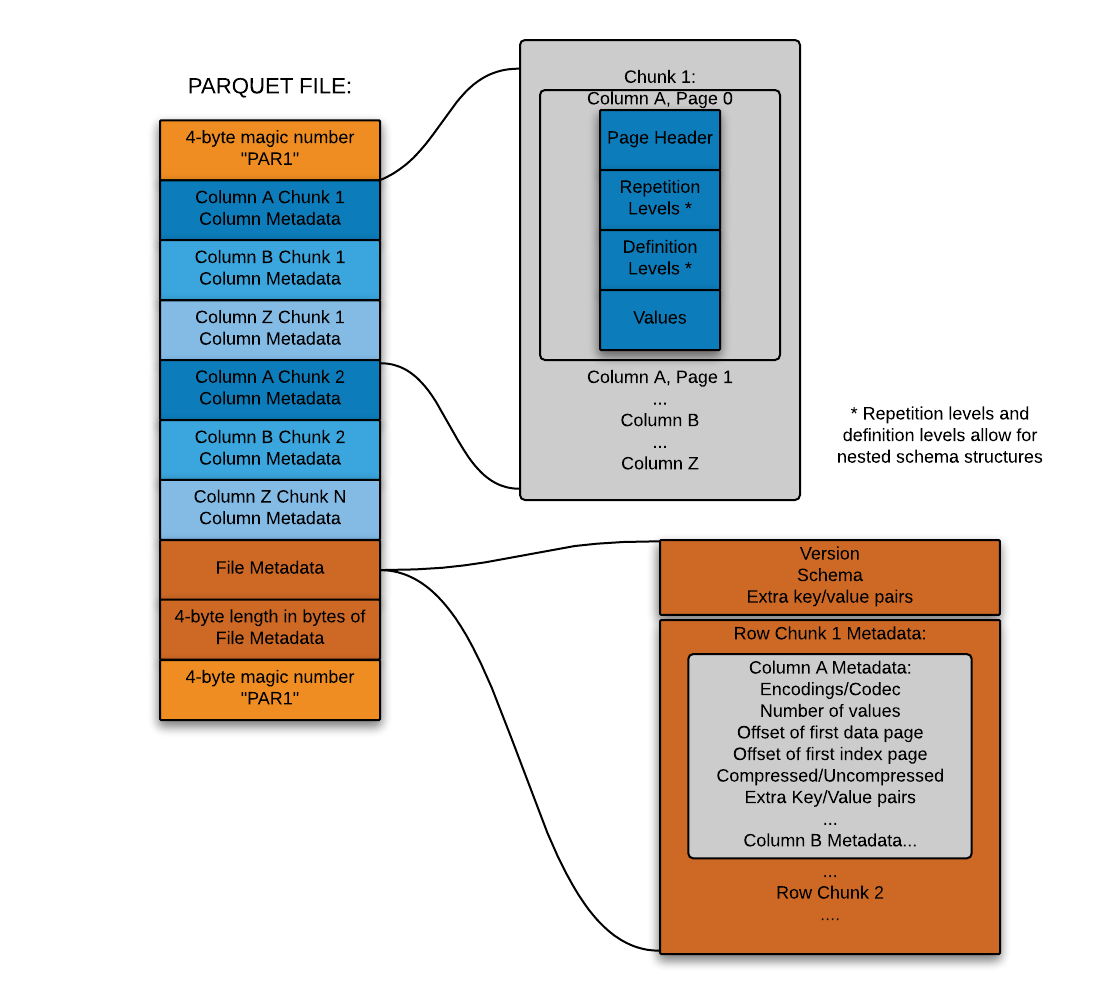
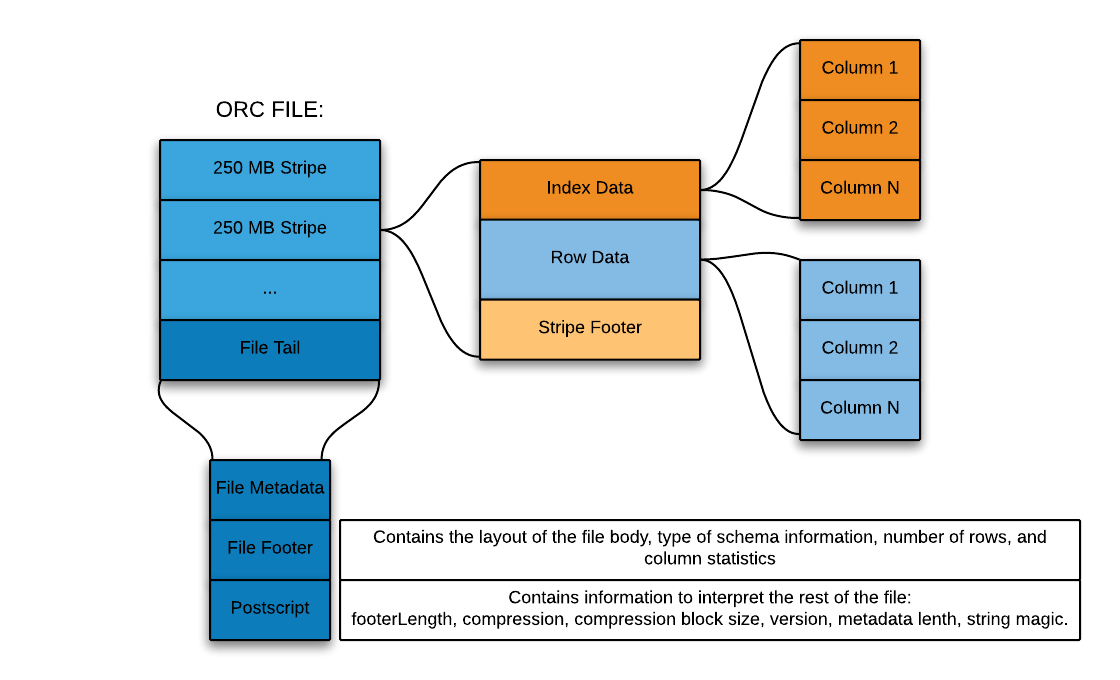
Data Formats to the Test
Background
We set out to create some tests so we can compare
the different data formats in terms of speed to write and
speed to read a file. You can recreate the tests in your own system with the code used in this blogpost which can be found here: SVDS Data Formats Repository.
Disclaimer: We didn’t design these tests to act as benchmarks. In fact, all of our tests ran in different platforms with different cluster sizes. Therefore, you might experience faster or slower times depending on your own system’s configuration. The main takeaway is the difference of the different data formats performance within the same system.
The Setup
We generated 3 different datasets to run the tests:
Narrow Dataset
10 columns
10 million rows
Resembles an Apache server log with 10
columns of information
Wide Dataset
1000 columns
4 million rows
Includes 15 columns of information and the
rest of the columns resemble choices. The overall dataset
might be something that keeps track of consumer choices or
behaviors
Large Dataset
1000 columns
302,924,000 rows
1 TB of data
Follows the same format as the wide dataset
We performed tests in Hortonworks, Cloudera, Altiscale, and
Amazon EMR distributions of Hadoop.
For the writing tests we measured how long it took Hive to write
a new table in the specified data format.
For the reading tests we used Hive and Impala to perform
queries and record the execution time each of the queries.
We used snappy compression for most of the data formats,
with the exception of Avro where we additionally used the deflate compression.
The queries ran to measure read speed, were in the form of:
SELECT COUNT(*) FROM TABLE WHERE …
Query 1 includes no additional conditions.
Query 2 includes 5 conditions.
Query 3 includes 10 conditions.
Query 4 includes 20 conditions.